 登陆
登陆题目详情
单选题 Q-learning的一个推广假设MDP问题的状态空间为S,动作空间为A,奖励函数为R(s, a, s'),衰减因子为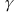 .我们的最终目标是学习一种机器人可以在现实世界中使用的策略.然而我们只能获得模拟软件的数据而非真实机器人的数据.该模拟软件是根据转移模型
.我们的最终目标是学习一种机器人可以在现实世界中使用的策略.然而我们只能获得模拟软件的数据而非真实机器人的数据.该模拟软件是根据转移模型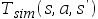 建立的,该模型与真实机器人转移模型
建立的,该模型与真实机器人转移模型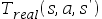 不同.在不改变仿真模拟软件的情况下,我们希望使用从模拟器中提取的样本来学习我们的真实机器人的q值.Q-learning的更新公式可以写为:
不同.在不改变仿真模拟软件的情况下,我们希望使用从模拟器中提取的样本来学习我们的真实机器人的q值.Q-learning的更新公式可以写为: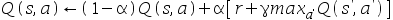 假设样本是从仿真模拟软件中抽取,则可以学到真实世界Q值得q值更新函数为:( )
假设样本是从仿真模拟软件中抽取,则可以学到真实世界Q值得q值更新函数为:( )
A. 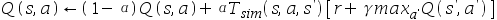
B. 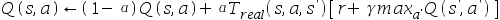
C. 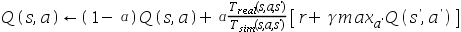
D. 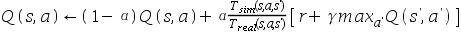
![[共享课]人工智能课程封面](https://tihai-oss-cloud.itihey.com/img/cf3bb414b5ea2367f316b2d3561124c7.jpg)
学科:[共享课]人工智能
时间:2024-11-25 00:25:44
相关题目
 题目1
题目1单选题
Q-learning的一个推广假设MDP问题的状态空间为S,动作空间为A,奖励函数为R(s, a, s'),衰减因子为<img src="https://tihai-oss-cloud.itihey.com/img/6494510fd9def2a2b5ff2ece65f0aa59.png">.我们的最终目标是学习一种机器人可以在现实世界中使用的策略.然而我们只能获得模拟软件的数据而非真实机器人的数据.该模拟软件是根据转移模型<img src="https://tihai-oss-cloud.itihey.com/img/11957ae58492f97996dbe380ad9ef63e.png">建立的,该模型与真实机器人转移模型<img src="https://tihai-oss-cloud.itihey.com/img/d445a3eb7e7399e60d0b14c9be70fd97.png">不同.在不改变仿真模拟软件的情况下,我们希望使用从模拟器中提取的样本来学习我们的真实机器人的q值.Q-learning的更新公式可以写为:<img src="https://tihai-oss-cloud.itihey.com/img/064d3e5c1d221745132312e5fea65740.png">假设样本是从仿真模拟软件中抽取,则可以学到真实世界Q值得q值更新函数为:( )A. <img src="https://tihai-oss-cloud.itihey.com/img/2805907a1e7b9a0547b332877297e4ae.png">B. <img src="https://tihai-oss-cloud.itihey.com/img/8a95a2284af97c60bbac298893a22bf8.png">C. <img src="https://tihai-oss-cloud.itihey.com/img/4ba696f660ebea22ad4fedd4feffe342.png">D. <img src="https://tihai-oss-cloud.itihey.com/img/e00b40e10d3a0eef658f14bc64d5a6c0.png">
题目2多选题
若一搜索树的树高有限且所有单步损耗均非负,则为每条边的损耗乘上一正常数w>0,以下树搜索算法中( )所得搜索路径保持不变A. BFSB. DFSC. UCSD. 无
题目3判断题
基于模型的强化学习涉及纯离线计算,而模型无关的强化学习需要与环境进行在线交互.( )A. 对B. 错
题目4多选题
在估价函数中,对于g(x)和h(x) 下面描述正确的是( )A. h(x)是从节点x到目标节点的最优路径的估计代价B. h(x)是从节点x到目标节点的实际代价C. g(x)是从初始节点到节点x的实际代价D. g(x)是从初始节点到节点x的最优路径的估计代价
题目5判断题
贪心搜索算法一定能找到最优解,因为它总是朝着离目标状态靠近的方向生成和扩展节点.( )A. 对B. 错
题目6多选题
宽度优先搜索与深度优先搜索有何区别是( )A. 宽度优先搜索的特点是先生成的节点先扩展B. 深度优先搜索的特点是先生成的节点先扩展C. 深度优先搜索的特点是先扩展最新产生的节点D. 宽度优先搜索的特点是先扩展最新产生的节点
题目7单选题
在等代价搜索算法中,总是选择( )的节点进行扩展A. 代价最小B. 深度最小C. 深度最大D. 代价最大
题目8多选题
下列关于MDP和RL的说法中,正确的有( )A. 从随机初始值开始的值迭代能收敛到<img src="https://tihai-oss-cloud.itihey.com/img/eb83dde30e38dd8e2deec363d6351a90.png">,其中<img src="https://tihai-oss-cloud.itihey.com/img/e82100bc61ebe5e50da86f6d69771a87.png">是最优策略B. Q-learning采用对最优动作价值函数的近似作为学习目标,与行动策略无关,是off-policy的C. 当具有确定性转移模型时,Q-learning不需要探索就能收敛到最优策略D. 在MDP问题中,一个较大的衰减因子(接近1)意味着代理更重视长期回报
题目9单选题
关于约束满足问题,以下说法错误的是( )A. 目标状态对应的动作路径消耗是一样的B. 约束满足问题存在最优解C. 在搜索时,回溯的原因是某些冲突导致搜索不能继续进行下去D. 前向检查是提前将不合理的值去掉的方法
题目10判断题
取值为负数的生存奖励总可以用小于1的衰减因子表示.( )A. 对B. 错
下载 题海APP
拍照搜题更快捷
- 海量题库
- 无搜索限制
- 快捷拍照搜题

